Designing a SIMD Algorithm from Scratch
I manually unrolled a byte-counting loop with four independent accumulators — the textbook ILP optimization — and it ran 2.08x *slower* than the plain loop. The plain loop that GCC had quietly autovec
High-signal content for senior engineers.
Real benchmarks. Real hardware. C++23/26 features that actually ship.
Published by a C++ practitioner with two decades of compiler abuse.
More about this site →
I manually unrolled a byte-counting loop with four independent accumulators — the textbook ILP optimization — and it ran 2.08x *slower* than the plain loop. The plain loop that GCC had quietly autovec
I spent a week reading llama.cpp's source. Not the GitHub README, not the model card — the actual C that runs when you type `./llama-cli -m llama-7b-q4.gguf`. What I found is one of the better-enginee
A `std::mutex`-protected `std::deque` is 12% faster than moodycamel::ConcurrentQueue when contention is low.
I measured the prefix sum on a Haswell i7-4790 with GCC 15.2.1 and `-O3 -march=native`. The scalar version hit 7.1 GB/s on 1MB arrays and held steady at 6.0–6.2 GB/s as I pushed to 1GB. ARM NEON on th
I built an immutable string-to-float-array map because I got tired of losing 6.8 nanoseconds every time I touched `std::unordered_map`. On an i7-4790 with GCC 15.2 and -O2, the immutable map delivers
For years I avoided thinking about memory orderings. I'd write `std::atomic<T>` with the default `std::memory_order_seq_cst`, and it worked. On x86-64, the CPU's strong memory model does the heavy lif
C++20 modules promised to fix the compile-time tax that header files impose. Five years on, GCC 16.1 is ready. The promise is sound. The tooling is not.
Feed `std::regex` a pathological pattern and a crafted input, and watch it spiral. Input length 16 characters: 4.48 milliseconds. Input length 18: 18 milliseconds. Input length 20: over a second. The
Compiler optimization passes live and die on tree traversal. LLVM's dominator analysis alone queries ancestor relationships thousands of times per function. A real C++ translation unit with heavy temp
Unsigned overflow wraps. That's the contract. C++ won't catch it, the CPU won't trap it. But your size calculation that wraps to a smaller buffer? That's a memory corruption vulnerability, and it's yo
You have a sorted array. Need to search it. `std::lower_bound`: O(log n), predictable, robust. This is the default solution. But my industry experience breeds skepticism. Every few months, a new paper
I've spent enough time staring at `perf stat` output to recognize a pattern: OpenMP's dynamic scheduler measures **55,593 ops/sec** on Zipf-distributed task costs with 512 tasks. That's about 18 micro
Llama.cpp's PR #22423 landed a kernel fusion for RMS_NORM + MUL in the ggml CPU backend a few weeks ago. The speedup: 1.60×. Consistently. Across dimension sizes, thread counts, even hardware variatio
Here's the uncomfortable truth: modern C++ standard library I/O becomes a bottleneck at scale. Traditional POSIX APIs introduce 1–10 microseconds of latency per operation due to syscall overhead and k
You've probably formatted a string in C++ more times than you've thought about how it works. Write a format string, pass some values; the library parses at runtime. It's a solved problem, shipped, sta
If you watched Ben Saks's CppCon 2025 'Back to Basics: Move Semantics' talk, you know what moves are and why the compiler calls them. That talk is solid. C++26 doesn't contradict it. What it does is t
I have written the `#ifdef` tower — `backtrace()` on Linux, `CaptureStackBackTrace()` on Windows, `dladdr` for symbol resolution on one side, `dbghelp.dll` on the other — more times than I care to adm
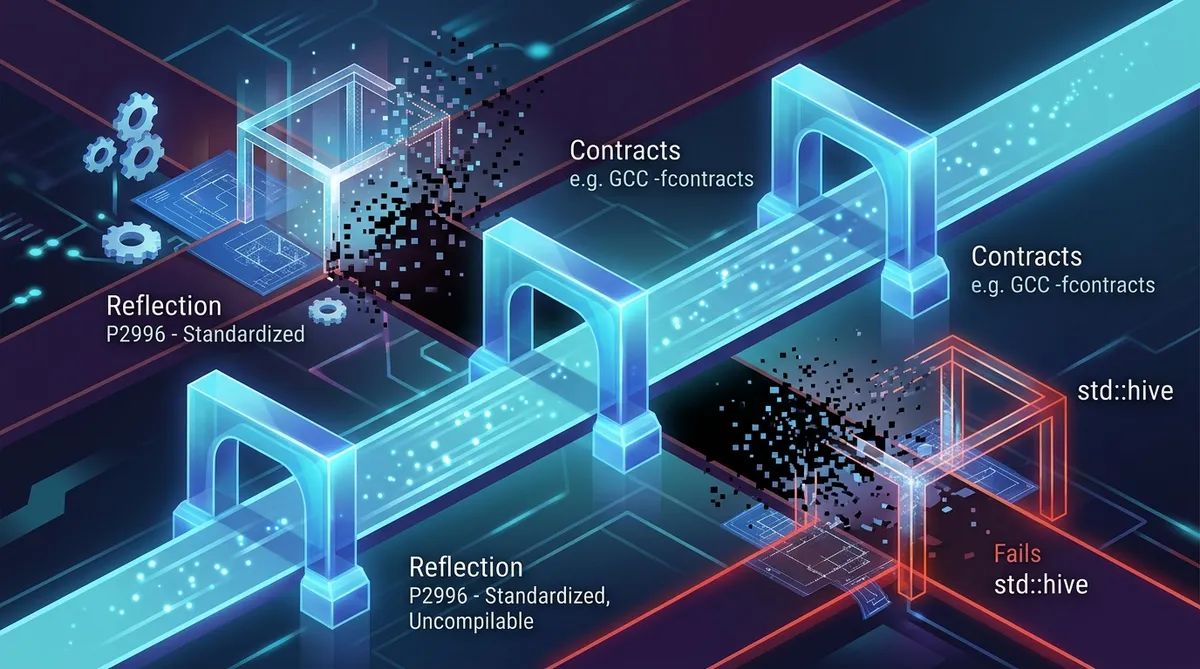
C++26 was voted out in March 2026. Contracts, reflection, and sender/receiver all shipped. I fed every major feature through GCC 15 and Clang 21 to see what actually compiles today.
I spent a week after using std::cpp 2026 trying to answer one question about profiles: do the checks cost anything? The proposal sounds good on paper — opt-in safety enforcement per translation unit,
GCC 15 — six years after C++20 — still does not enable modules with -std=c++20. The tooling gap is real, and it is not closing fast.
That's GCC 15.2.1, `-O2 -std=c++26`, on an i7-4790 at 3.6 GHz. The function under test does one multiply. One precondition is checked.
That's the whole story. I took a virtual-dispatch interpreter loop — the textbook PGO target — instrumented it, trained it on a representative workload, and recompiled. Both GCC 15.2.1 and Clang 21.1.
The `-fno-exceptions` build flag and `int` return codes. Every embedded C++ codebase I've worked on has both, and the pattern is always the same: return an error code, take an output pointer, hope the
Your threads are doing independent work on independent data, and yet adding a second thread makes everything six times slower. This is false sharing, and it hides in struct layouts and thread-local counters across more production codebases than anyone wants to admit.